

“Sometimes, I just wanna rewind”
– Charli xcx

há uma percepção entre os usuários da internet de que tudo o que é publicado online deixa rastros e persiste indefinidamente. o que temos vivenciado nos últimos tempos, no entanto, é uma realidade onde links param de funcionar (ou link rot), sites ficam indisponíveis, conteúdos são removidos, redes sociais são desativadas, e por aí vai. coisas somem da internet.
quem já não tentou acessar um site depois de muito tempo e se frustrou por ele ter saído do ar? ou então se arrependeu por ter deletado o perfil de alguma rede social sem ter salvo os álbuns de fotos e postagens? que empolgante seria ainda ter acesso ao meu Hotmail, Fotolog, MySpace, ler um tweet antigo, fuçar as comunidades do Orkut das quais fazia parte, revisitar blogs, ou só me entreter com as interfaces divertidas de portais daquela época.
esse “apagamento” digital pode ter ocorrido de maneira intencional da nossa parte, por falta de interesse ou irrelevância diante do próprio conteúdo. ou a plataforma simplesmente deixou de existir com o tempo, e, consequentemente, nosso breve período por lá foi extinto sem explicação ou aviso prévio. uma parte da sua vida se foi e provavelmente nunca será recuperada.
When web-hosting company Glitch.com shut down overnight, dozens of playful self-made sites from our past workshops vanished, replaced by the error screen ‘Well. You found a glitch.’ All that remains are tiny thumbnail previews we rescued onto an Are.na board, like digital fossils of a lost web.”
– Phreaking Collective

por que arquivar?
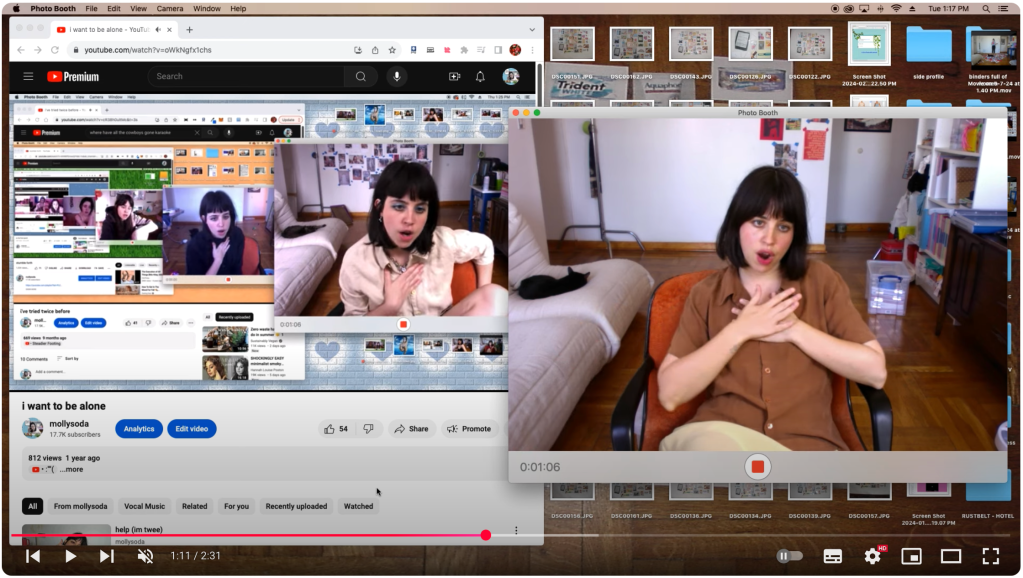
assim como objetos e documentos físicos, acredito que as mídias digitais podem servir como testemunhos tangíveis da nossa vida e materialização da memória. quem desenvolve essa visão com genialidade é a artista americana Molly Soda, conhecida por suas criações que incorporam material de seu extenso acervo digital acumulado desde o começo do século – também referido como digital clutter –, explorando identidade e presença online através de performances com vídeos de webcam, selfies, gifs e colagens digitais.
em sua série Desktop Dump, ela captura e publica periodicamente o conteúdo caótico da sua área de trabalho antes de realizar uma limpeza digital, resultando em um arquivo online de capturas de telas. na obra-playlist Steadier Footing, a artista revisita e remixa anualmente seu vídeo publicado no Youtube em 2013, performando a mesma música no mesmo ambiente de seu quarto e enquadramento: um loop de fragmentos de diferentes períodos da vida de uma usuária da internet. recentemente, criou livros de artista em formato de fichário com milhares de seus arquivos compilados impressos.
ela já comentou da importância de salvar e preservar o histórico digital pessoal, sempre refletindo sobre o quanto esse conteúdo será valorizado (e lembrado com carinho) no futuro. e que, infelizmente, já é tarde demais para preservar certas coisas.
para além do âmbito pessoal e afetivo, a preservação de informações e documentos digitais pode desempenhar um papel importante na sobrevivência da memória coletiva. como grande parte da nossa cultura hoje acontece online, sem a dedicação de arquivistas e organizações fazendo esse tipo de trabalho, corremos o risco de perder o registro de quem somos.
estamos vivendo um cenário em que grandes quantidades de informações digitais são perdidas ou tornadas permanentemente irrecuperáveis, incapazes de serem acessadas e utilizadas por gerações futuras. um estudo recente revelou que 38% dos sites existentes em 2013 já não estão mais acessíveis. alguns termos já usados para descrever esse fenômeno incluem Vanishing Culture (“cultura em extinção”), Digital Decay (“decadência digital”), e Digital Dark Age (“idade das trevas digital”).
na atual conjuntura, onde as big techs monopolizam e ditam o panorama digital com suas plataformas alinhadas a interesses corporativos e políticos, somada à fragilidade da informação online diante da constante evolução tecnológica, em que ferramentas e dispositivos rapidamente se tornam obsoletos, a preservação e o acesso público aos recursos da web se tornam ainda mais urgentes.
“Librarians are what the internet is aching for—people on task to care about the past, with respect to the past and also to what it shall bequeath to the future.”
– Joanne McNeil, Lurking: How a Person Became a User

atualmente, a maior e mais importante instituição de preservação digital é o Internet Archive <3, uma organização sem fins lucrativos fundada em 1996 e sediada na Califórnia. a principal biblioteca da nossa vida digital faz um trabalho incrível de arquivamento e conta com a ajuda de voluntários e doações para digitalizar materiais como livros e documentos históricos e armazenar milhões arquivos digitais (áudios, filmes, softwares, gifs) em seus servidores. sua missão é “fornecer acesso universal a todo o conhecimento”, oferecendo acesso gratuito ao público em geral.
em 2001, a instituição lançou a Wayback Machine, uma ferramenta que coleta e armazena cópias de sites, permitindo que usuários acessem versões arquivadas de páginas da web. sua tecnologia possibilita a navegação em sites que já foram extintos, como páginas criadas no GeoCities. a ferramenta ainda oferece a opção Save Page Now (“Salve a página agora”), que permite que qualquer indivíduo inclua novos conteúdos no arquivo. a previsão é de que em Outubro deste ano, a Wayback Machine alcance a marca histórica de 1 trilhão de sites arquivados.
outros exemplos de projetos e organizações menores que fazem esse tipo de trabalho são o Webrecorder, Conifer (parte da Rhizome.org), ArchiveBox e Archive.today.
“Those numbers are wonderful and should be celebrated, but it is important to note that the Wayback Machine does not archive everything. Worse, there is no other comparable public archive: without the Wayback Machine, these sites very well may have permanently vanished from public access. […] The promise of the internet as a public repository of knowledge carries on through the daily labor of open access digital archives and their custodians. The Internet Archive, as one such archive, provides one guard against vanishing culture. However, it cannot be the only mechanism for historical preservation.”
– Luca Messarra, Vanishing Culture: A Report on Our Fragile Cultural Record
ainda assim, é arriscado depender de poucos grupos e plataformas para a preservação do patrimônio cultural da internet. com ciberataques cada vez mais frequentes direcionados à bibliotecas e instituições de memórias – o Internet Archive ficou temporariamente fora do ar em 2024 devido a um ataque, e o site da British Library sofreu disrupção em 2023, com parte de seu catálogo ainda não recuperado –, precisamos agir para assegurar que conteúdos digitais continuarão a existir. ao fim, é um esforço coletivo e colaborativo.

no Brasil ainda não há uma política oficial de preservação da web, e muitos sites antigos sobrevivem graças ao Internet Archive. mas existem alguns núcleos que trabalham com pesquisa e estudo na área, entre eles o NUAEWB e o Projeto Graúna. um documento inédito sobre o assunto no país foi publicado no ano passado, e está disponível online para consulta.
arquivamento da web
o arquivamento da web é o processo de preservação do conteúdo da World Wide Web, que envolve a captura e o armazenamento de informações de sites, plataformas de mídia social e outros recursos online, garantindo que possam ser acessados e utilizados no futuro. essa prática pode ser realizada tanto por profissionais quanto por amadores, e possibilita a preservação do histórico de conteúdos online, assegurando que informações importantes não se percam quando sites e outros recursos são atualizados ou desativados.
“[…] o arquivamento da web permite escrever a história da web, que é uma condição necessária para a compreensão da Internet do presente, bem como de novas formas emergentes de Internet.”
– Moisés Rockembach, Arquivamento da web e preservação digital
indivíduos podem arquivar conteúdo que seja relevante para seus interesses pessoais, estudos ou projetos, incluindo banco de dados; artigos da Wikipédia; fanfics; videos; Tiktoks; sites diversos; exposições online de museus; fóruns de comunidade; notícias; portfólios digitais; blogs; Substacks; postagens de pessoas queridas que já se foram; galeria de fotos; hashtags, etc.
existem algumas ferramentas disponíveis para fazer o arquivamento da web de forma manual, aqui vou apresentar algumas opções. o mais indicado é você mesmo fazer o download e armazenar em algum local onde tenha controle total. também recomendo fazer backups e manter cópias offline do seu conteúdo sempre que possível. algumas plataformas de redes sociais já possuem a opção com instruções de como exportar seus dados e mídias.
Webrecorder
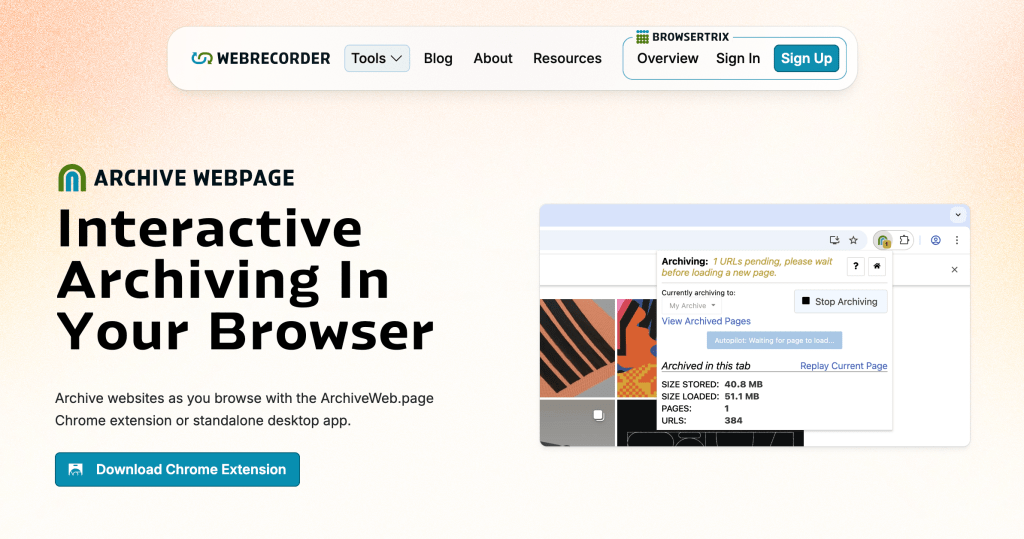
o Archive Webpage é uma ferramenta do Webrecorder que permite fazer cópias de sites, e funciona gravando seu movimento enquanto navega em determinada página. ele documenta seu tráfego em formato padrão de arquivamento da web (WARC ou WACZ), que mais tarde pode ser reproduzido offline, ou hospedado e integrado em outro local como um arquivo navegável.
diferente de uma gravação de tela, o usuário pode interagir com as páginas capturadas, e até percorrer diferentes caminhos que não foram registrados durante o processo de arquivamento. além disso, o Archive Webpage permite arquivar páginas com paywalls e até o conteúdo gerado algoritmicamente, como feeds de redes sociais. nesse caso, escolha armazenar o arquivo em locais privados, já que pode incluir informações sigilosas como credenciais de login.
existem duas opções de como usar a ferramenta: instalando a extensão para Chrome, que você pode usar enquanto navega, ou a aplicação para desktop.
todas as ferramentas criadas pelo Webrecorder são open-source, isso é, os códigos-fonte desses softwares estão disponíveis ao público para uso, modificação e distribuição de forma gratuita e colaborativa. para sites maiores e mais complexos, eles oferecem o serviço pago de arquivamento Browsertrix.
⭑ passo 1: capturar (fazer cópias)
-
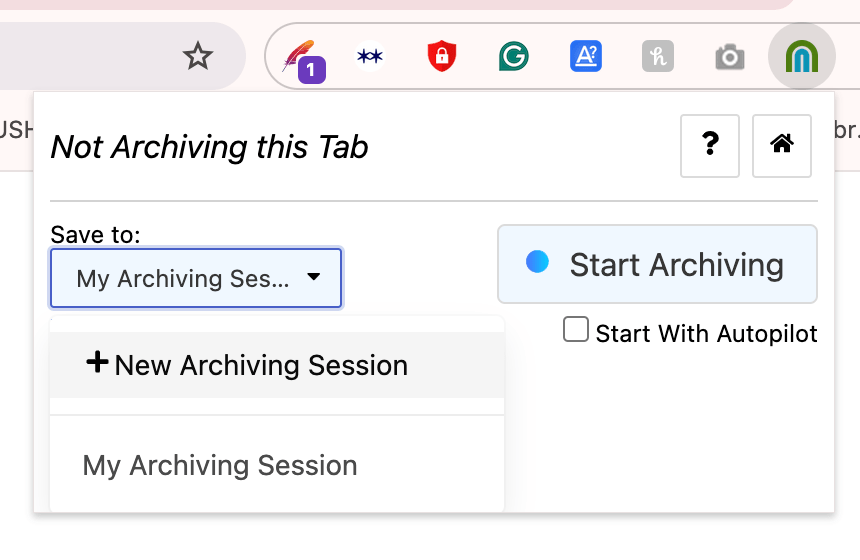
- Depois de instalar a extensão do Archive Webpage para Chrome, acesse a página que você deseja preservar;
- Crie uma coleção: Clique no ícone da extensão, e uma janela irá aparecer. Embaixo de Save to, selecione a opção New Archiving Session. Dê um nome para a coleção e clique no ícone de check;
-
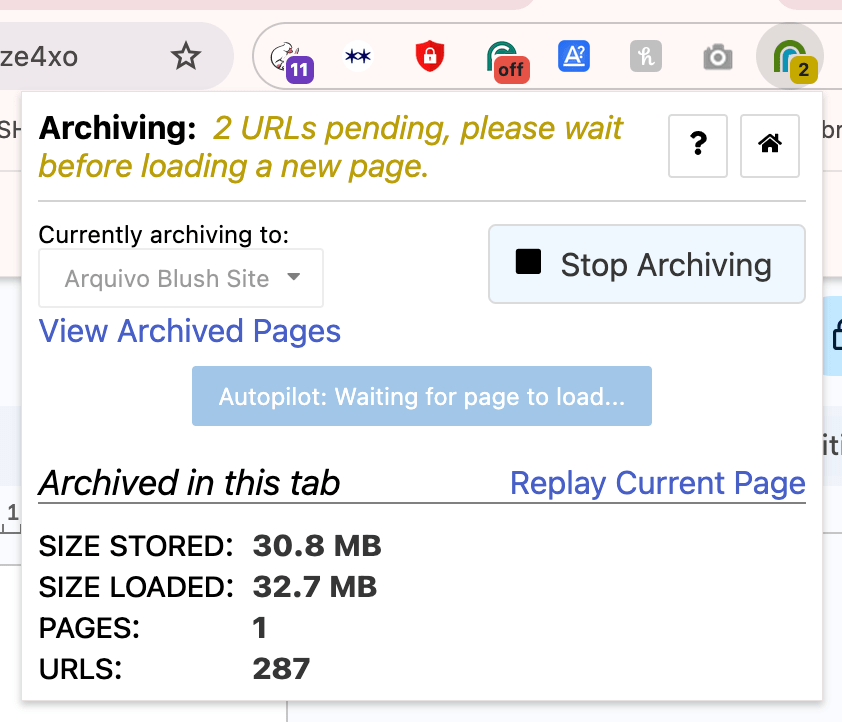
- Dê início ao arquivamento: Clique no botão Start Archiving. A página irá recarregar e um banner “‘Webrecorder ArchiveWeb.page’ started debugging this browser” vai aparecer no topo (isso é normal, e está relacionado à maneira como a ferramenta foi programada);

-
- Sessão de arquivamento: Hora de arquivar! Enquanto navegamos página por página, cada uma delas é capturada na nossa coleção. Role e clique nas sessões das páginas, menus, links e mídias que gostaria de arquivar: Se houver um vídeo do Youtube integrado, por exemplo, certifique-se de que ele esteja carregado;
- Verifique a extensão: Se houver um aviso em amarelo, significa que a gravação da página está sendo processada. Não finalize a sessão ainda;
-
- Encerre a sessão: Clique em Stop Archiving.
se encontrar algum erro ou houver dúvidas, consulte o guia completo ou entre em contato com o suporte.
uma vez criados, os arquivos ficam salvos no browser e podem ser acessados a qualquer momento através do ícone da homepage na extensão. as capturas abrem no sistema de replay de arquivos do Webrecorder (ele carrega diretamente do seu arquivo, e não da internet). você pode organizar seus arquivos em diversas coleções e procurar por páginas pelo endereço (URL), ou pelo texto encontrado nesta página.
⠂⠄⠄⠂⠁⠁⠂⠄⠄⠂⠁⠁⠂⠄⠄⠂
⭑ passo 2: armazenar (tornar as cópias utilizáveis no futuro)
você pode baixar uma coleção inteira ou páginas específicas e escolher entre formatos WARC ou WACZ – esse último é o mais recomendado, pois inclui os arquivos do WARC mais os metadados. esses tipos de arquivo, convenientemente, contêm tudo o que é necessário para o acesso à captura: arquivos de HTML e CSS, mídias (imagens, vídeos, gifs), textos, índices, links, arquivos de JavaScript que fazem a página dinâmica, e metadados. arquivos WARC ou WACZ não operam de maneira autônoma, eles dependem de alguma tecnologia para serem reproduzidos.
a nomenclatura dos arquivos também é importante para que você e, potencialmente, outras pessoas possam localizá-los e lembrar do que se tratam no futuro. algumas convenções para nomear arquivos são:
- data de captura (use AAAA-MM-DD para facilitar a classificação por data);
- nome da instituição ou site;
- sufixo de domínio (.edu, .org, .com, etc).
por exemplo, nomeando corretamente o arquivo WACZ do site da Blush, capturado no dia de hoje, ficaria “2025-08-06-arquivo-blush-com”. outra maneira de deixar os arquivos organizados é criar pastas por tópicos, por plataforma, e/ou por tipo de site (por exemplo, “sites de notícia”).
⠂⠄⠄⠂⠁⠁⠂⠄⠄⠂⠁⠁⠂⠄⠄⠂
⭑ passo 3: acessar (visualizar as cópias)
para visualizar arquivos da web em formato WARC ou WACZ, é necessária uma ferramenta de replay. o Replay Webpage é o sistema do Webrecorder para reproduzir arquivos nesses formatos. assim como o Archive Webpage, ele funciona tanto pelo browser como através da aplicação para desktop.
mesmo no browser, o Replay Webpage opera de forma client-side, o que significa que quando você carrega um arquivo, ele não está sendo processado e enviado para nenhum servidor ou outro lugar, tudo acontece no ambiente local na sua máquina. isso faz com que o processo seja totalmente privado e que você tenha o controle.
para visualizar no browser, basta carregar seu arquivo na página:
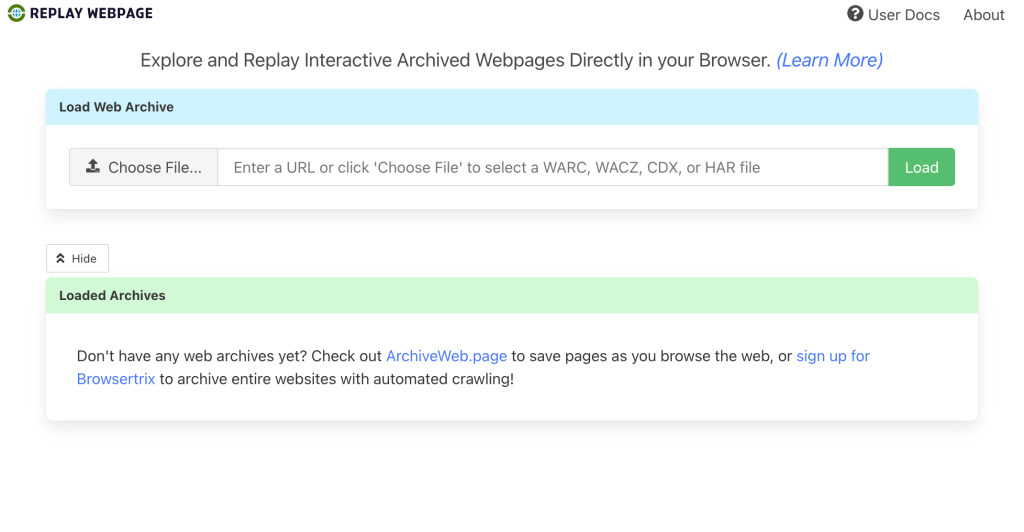
Wayback Machine
como mencionado anteriormente, o projeto da Internet Archive possibilita que os usuários adicionem páginas da web ao diretório da ferramenta. diferente do Webrecorder, o conteúdo ficará acessível ao público.
para arquivar, acesse Save Page Now e inclua o endereço da página que será capturada. lembre-se de selecionar a opção “Email me a WACZ with the results” para receber uma cópia do conteúdo arquivado para ser armazenado localmente na sua máquina. clique em Save Page. o processo pode levar um tempo e, após alguns minutos, você receberá um email com o link para download do arquivo no formato WACZ.
a Wayback Machine também está disponível como uma extensão do Chrome.
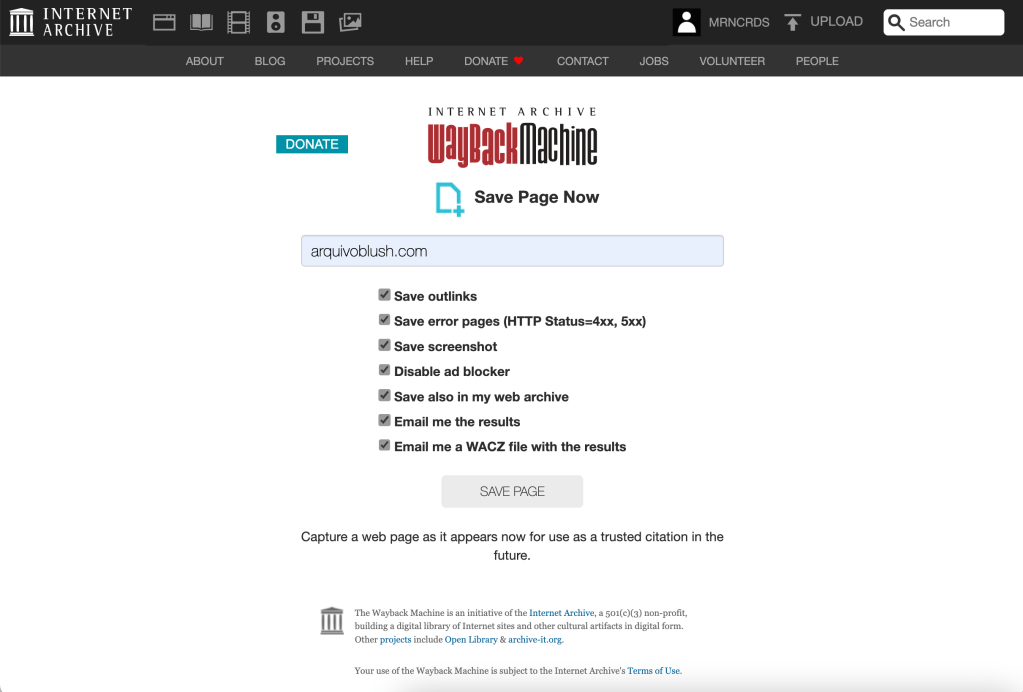
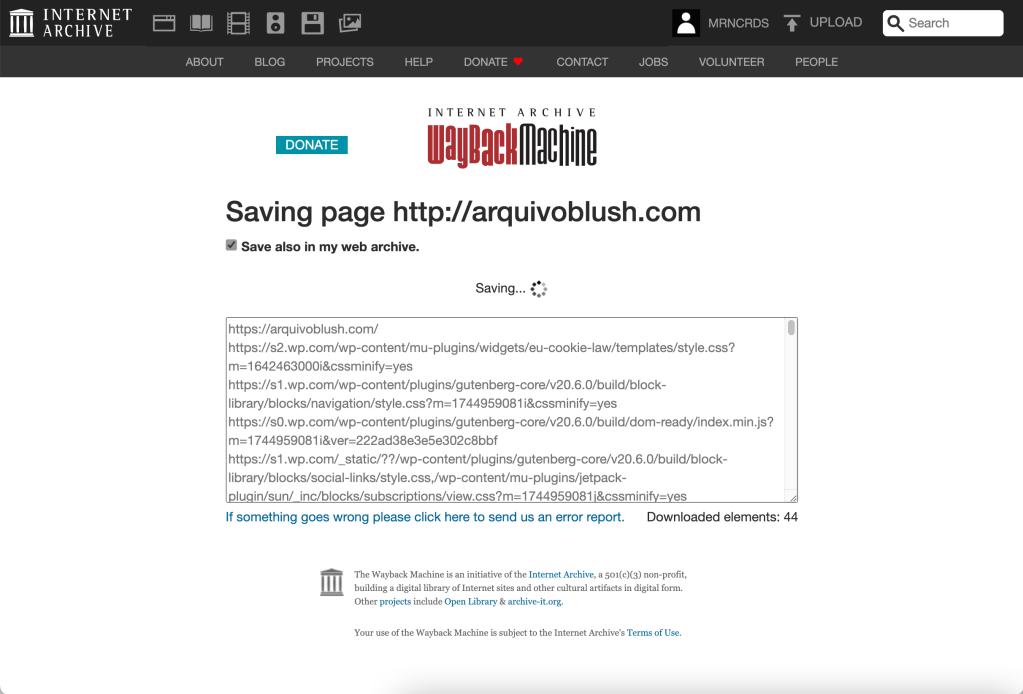
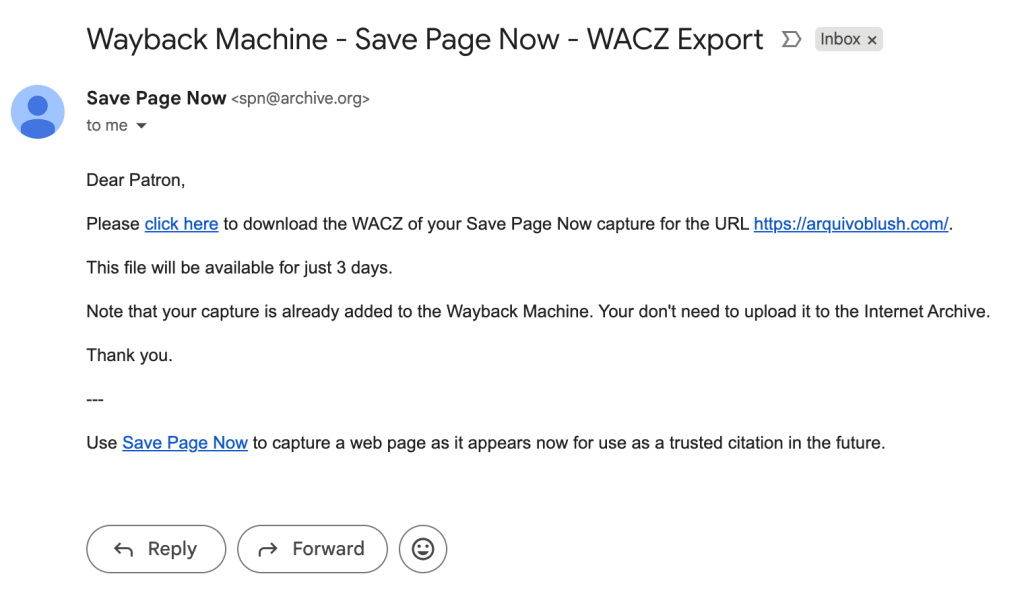
enquanto montava esse post, lembrei que ainda tinha acesso ao meu antigo Tumblr e corri para fazer o download de todo o meu histórico e conteúdo. o processo é bem simples: em configurações, selecione o blog que deseja exportar na barra lateral. role até o final da página e clique em Exportar [nome do blog]. uma mensagem indicando o início do download vai aparecer e o processo pode demorar alguns minutos.
fiquei feliz de ver que as mídias que compartilhei há mais de dez anos ficaram conservadas, e agora vivem no meu computador. também arquivei sites que desenvolvi e outros pelos quais tenho um carinho especial. quero continuar a preservar partes da internet que me fazem amá-la, enquanto elas ainda existem.
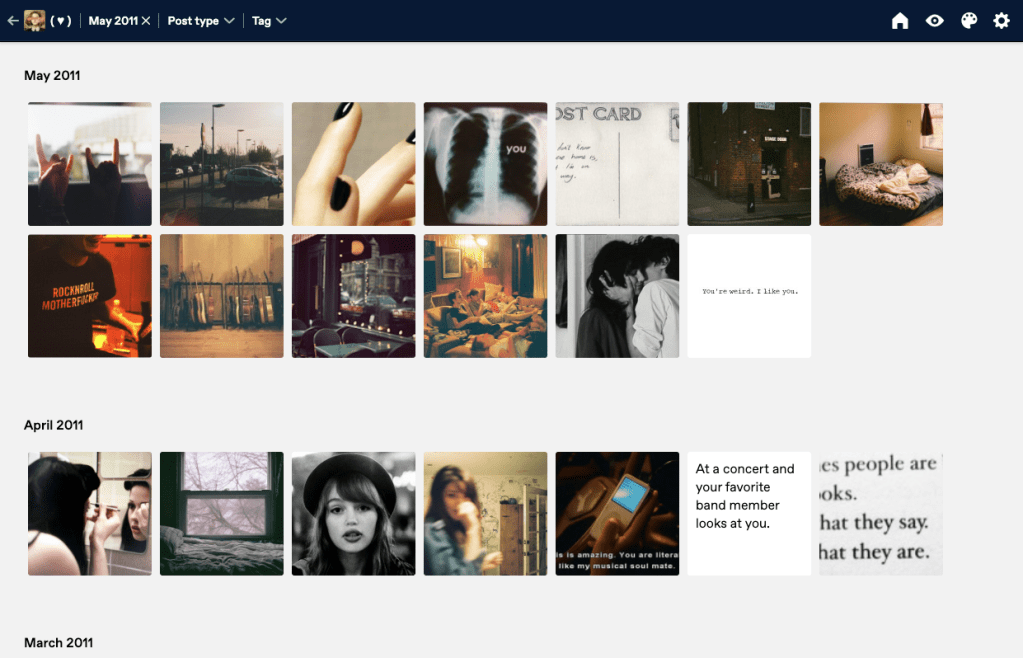
espero que este post sirva de incentivo à prática de arquivar e de preservar o seu (e o nosso) passado digital. já usa alguma dessas ferramentas ou outra que não foi citada aqui? conta pra gente!

links e materiais de referência
esse post foi inspirado na zine DIY Web Archiving: For the web (& world) you care about, disponível para leitura aqui (em inglês).
- lista extensa com materiais e ferramentas de arquivamento web (em inglês);
- Dombrowski, Q., Walsh, T., Kijas, A., Kreymer, I. & Visconti, A. DIY Web Archiving: For the Web (& World) You Care About. Zine Bakery Bakeshop #2; Version 4; January 30, 2025. Charlottesville, VA, U.S.A. Available at: https://zinebakery.com/homemade-zines/bakeshop-2- diywebarchiving
- Messarra, L., Freeland, C. & Ziskina, J. Vanishing Culture: Preserving Our Fragile Cultural Record in the Digital Age, Internet Archive. United States of America, 2024. Available at: https://archive.org/details/vanishing-culture-report
- Rockembach, Moisés; Pavão, Caterina Groposo. Arquivamento da web e preservação digital. São Paulo: Pimenta Cultural, 2024. Disponível em:
https://www.pimentacultural.com/wp-content/uploads/2024/06/eBook_arquivamento-web.pdf
texto e arte por marina


Deixe um comentário